How to Make Your Product The Ferrari Of Deepseek
페이지 정보

본문
 The very recent, state-of-artwork, open-weights mannequin DeepSeek R1 is breaking the 2025 news, excellent in many benchmarks, with a brand new integrated, end-to-end, reinforcement studying strategy to giant language mannequin (LLM) coaching. We pretrain DeepSeek-V2 on a excessive-quality and multi-supply corpus consisting of 8.1T tokens, and additional perform Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to totally unlock its potential. This approach is referred to as "cold start" coaching as a result of it didn't embody a supervised superb-tuning (SFT) step, which is usually a part of reinforcement learning with human feedback (RLHF). Starting JavaScript, studying fundamental syntax, knowledge varieties, and DOM manipulation was a sport-changer. One plausible purpose (from the Reddit submit) is technical scaling limits, like passing data between GPUs, or handling the amount of hardware faults that you’d get in a coaching run that dimension. But when o1 is costlier than R1, having the ability to usefully spend extra tokens in thought may very well be one reason why. 1 Why not simply spend 100 million or extra on a training run, when you have the money? It is said to have value just 5.5million,comparedtothe5.5million,comparedtothe80 million spent on models like these from OpenAI. I already laid out final fall how every facet of Meta’s business benefits from AI; a big barrier to realizing that imaginative and prescient is the cost of inference, which signifies that dramatically cheaper inference - and dramatically cheaper coaching, given the necessity for Meta to stay on the innovative - makes that vision far more achievable.
The very recent, state-of-artwork, open-weights mannequin DeepSeek R1 is breaking the 2025 news, excellent in many benchmarks, with a brand new integrated, end-to-end, reinforcement studying strategy to giant language mannequin (LLM) coaching. We pretrain DeepSeek-V2 on a excessive-quality and multi-supply corpus consisting of 8.1T tokens, and additional perform Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to totally unlock its potential. This approach is referred to as "cold start" coaching as a result of it didn't embody a supervised superb-tuning (SFT) step, which is usually a part of reinforcement learning with human feedback (RLHF). Starting JavaScript, studying fundamental syntax, knowledge varieties, and DOM manipulation was a sport-changer. One plausible purpose (from the Reddit submit) is technical scaling limits, like passing data between GPUs, or handling the amount of hardware faults that you’d get in a coaching run that dimension. But when o1 is costlier than R1, having the ability to usefully spend extra tokens in thought may very well be one reason why. 1 Why not simply spend 100 million or extra on a training run, when you have the money? It is said to have value just 5.5million,comparedtothe5.5million,comparedtothe80 million spent on models like these from OpenAI. I already laid out final fall how every facet of Meta’s business benefits from AI; a big barrier to realizing that imaginative and prescient is the cost of inference, which signifies that dramatically cheaper inference - and dramatically cheaper coaching, given the necessity for Meta to stay on the innovative - makes that vision far more achievable.
DeepSeek’s innovation has caught the eye of not just policymakers but also business leaders akin to Mark Zuckerberg, who opened war rooms for engineers after DeepSeek’s success and who at the moment are keen to grasp its components for disruption. Note that there are other smaller (distilled) DeepSeek models that you will see on Ollama, for instance, that are only 4.5GB, and could be run locally, but these are not the same ones as the main 685B parameter mannequin which is comparable to OpenAI’s o1 mannequin. In this text, I will describe the four primary approaches to constructing reasoning fashions, or how we are able to enhance LLMs with reasoning capabilities. An affordable reasoning model is perhaps low-cost because it can’t assume for very lengthy. The reward mannequin was repeatedly up to date during training to avoid reward hacking. Humans, together with top gamers, want plenty of practice and training to turn out to be good at chess. When do we need a reasoning mannequin? DeepSeek's downloadable mannequin shows fewer signs of constructed-in censorship in contrast to its hosted models, which seem to filter politically sensitive matters like Tiananmen Square.
In distinction, a question like "If a prepare is transferring at 60 mph and travels for three hours, how far does it go? Most fashionable LLMs are capable of fundamental reasoning and can answer questions like, "If a train is shifting at 60 mph and travels for 3 hours, how far does it go? It's built to assist with varied duties, from answering questions to producing content, like ChatGPT or Google's Gemini. In this article, I outline "reasoning" as the technique of answering questions that require complex, multi-step generation with intermediate steps. Additionally, most LLMs branded as reasoning fashions immediately embrace a "thought" or "thinking" course of as a part of their response. Part 2: DeepSeek VS OpenAI: What’s the difference? Before discussing 4 principal approaches to constructing and bettering reasoning models in the following part, I want to briefly define the DeepSeek R1 pipeline, as described in the Free DeepSeek Chat R1 technical report. More particulars can be lined in the following section, where we focus on the four fundamental approaches to building and bettering reasoning models. Now that we've got outlined reasoning fashions, we can move on to the more fascinating part: how to build and improve LLMs for reasoning tasks.
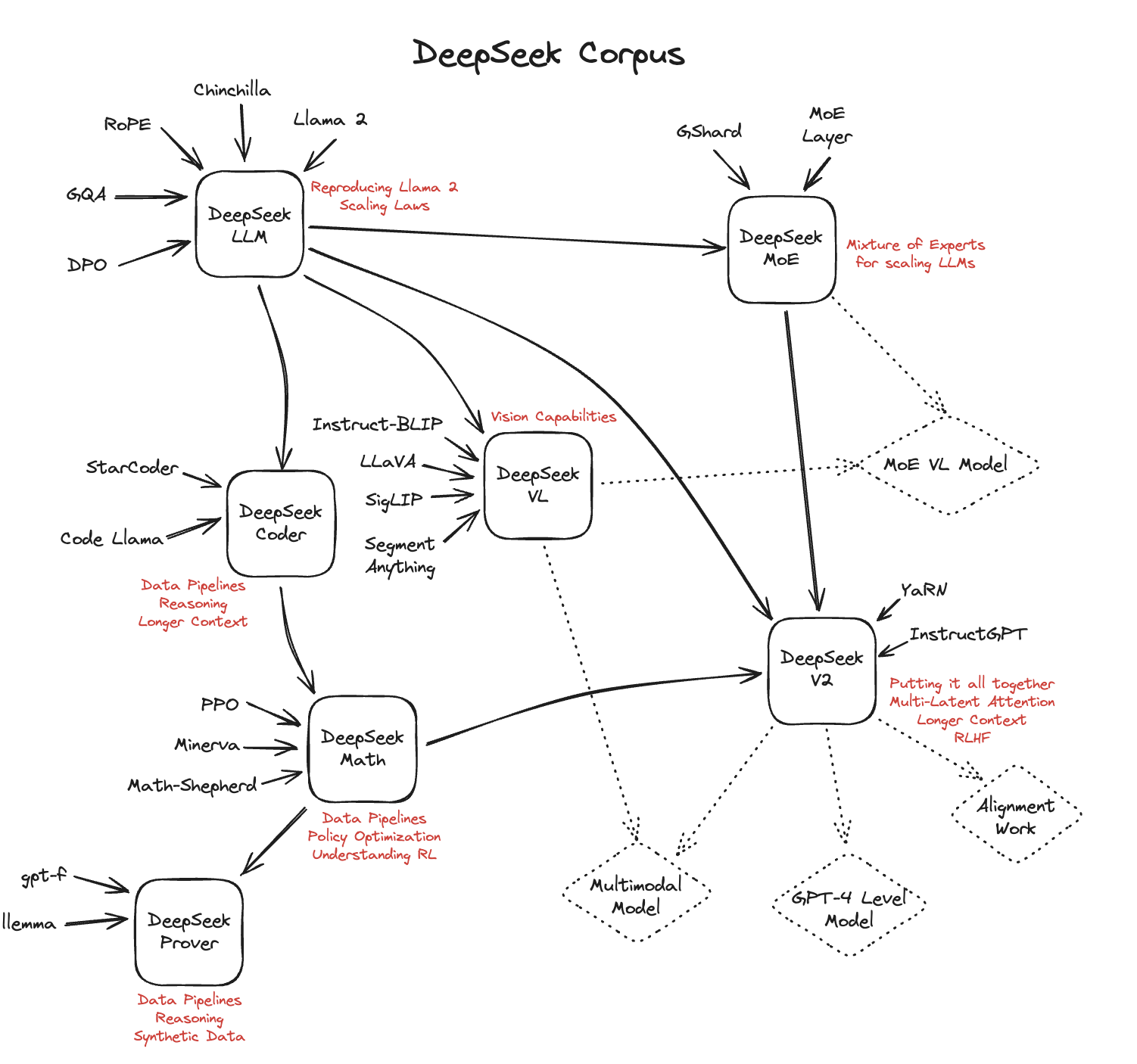 Reinforcement learning. DeepSeek used a large-scale reinforcement studying method focused on reasoning tasks. If you work in AI (or machine studying usually), you are in all probability familiar with vague and hotly debated definitions. Reasoning models are designed to be good at advanced tasks similar to solving puzzles, advanced math issues, and challenging coding tasks. This means we refine LLMs to excel at advanced duties which might be finest solved with intermediate steps, similar to puzzles, advanced math, and coding challenges. " So, immediately, once we check with reasoning models, we usually imply LLMs that excel at extra advanced reasoning duties, reminiscent of fixing puzzles, riddles, and mathematical proofs. " does not contain reasoning. As an illustration, reasoning models are sometimes dearer to use, more verbose, and sometimes extra prone to errors as a consequence of "overthinking." Also right here the simple rule applies: Use the fitting instrument (or kind of LLM) for the duty. Specifically, patients are generated via LLMs and patients have particular illnesses based on real medical literature.
Reinforcement learning. DeepSeek used a large-scale reinforcement studying method focused on reasoning tasks. If you work in AI (or machine studying usually), you are in all probability familiar with vague and hotly debated definitions. Reasoning models are designed to be good at advanced tasks similar to solving puzzles, advanced math issues, and challenging coding tasks. This means we refine LLMs to excel at advanced duties which might be finest solved with intermediate steps, similar to puzzles, advanced math, and coding challenges. " So, immediately, once we check with reasoning models, we usually imply LLMs that excel at extra advanced reasoning duties, reminiscent of fixing puzzles, riddles, and mathematical proofs. " does not contain reasoning. As an illustration, reasoning models are sometimes dearer to use, more verbose, and sometimes extra prone to errors as a consequence of "overthinking." Also right here the simple rule applies: Use the fitting instrument (or kind of LLM) for the duty. Specifically, patients are generated via LLMs and patients have particular illnesses based on real medical literature.
- 이전글Match Your Italian Vegetarian Meals With Canned Tomatoes 25.03.23
- 다음글What Involving House Is Right For You: Essential Considerations 25.03.23
댓글목록
등록된 댓글이 없습니다.