Deepseek: Again To Basics
페이지 정보

본문
 DeepSeek 모델은 처음 2023년 하반기에 출시된 후에 빠르게 AI 커뮤니티의 많은 관심을 받으면서 유명세를 탄 편이라고 할 수 있는데요. In line with Forbes, DeepSeek used AMD Instinct GPUs (graphics processing models) and ROCM software program at key phases of mannequin growth, particularly for DeepSeek-V3. The startup made waves in January when it launched the total version of R1, its open-supply reasoning model that may outperform OpenAI's o1. AGI. Starting subsequent week, we'll be open-sourcing 5 repos, sharing our small but sincere progress with full transparency. However, in contrast to ChatGPT, which solely searches by counting on certain sources, this feature may reveal false data on some small websites. Therefore, users need to confirm the knowledge they obtain in this chat bot. DeepSeek emerged to advance AI and make it accessible to customers worldwide. Again, just to emphasise this level, all of the selections DeepSeek made in the design of this model only make sense in case you are constrained to the H800; if DeepSeek had entry to H100s, they in all probability would have used a larger coaching cluster with a lot fewer optimizations particularly focused on overcoming the lack of bandwidth. By 2021, he had already constructed a compute infrastructure that would make most AI labs jealous!
DeepSeek 모델은 처음 2023년 하반기에 출시된 후에 빠르게 AI 커뮤니티의 많은 관심을 받으면서 유명세를 탄 편이라고 할 수 있는데요. In line with Forbes, DeepSeek used AMD Instinct GPUs (graphics processing models) and ROCM software program at key phases of mannequin growth, particularly for DeepSeek-V3. The startup made waves in January when it launched the total version of R1, its open-supply reasoning model that may outperform OpenAI's o1. AGI. Starting subsequent week, we'll be open-sourcing 5 repos, sharing our small but sincere progress with full transparency. However, in contrast to ChatGPT, which solely searches by counting on certain sources, this feature may reveal false data on some small websites. Therefore, users need to confirm the knowledge they obtain in this chat bot. DeepSeek emerged to advance AI and make it accessible to customers worldwide. Again, just to emphasise this level, all of the selections DeepSeek made in the design of this model only make sense in case you are constrained to the H800; if DeepSeek had entry to H100s, they in all probability would have used a larger coaching cluster with a lot fewer optimizations particularly focused on overcoming the lack of bandwidth. By 2021, he had already constructed a compute infrastructure that would make most AI labs jealous!
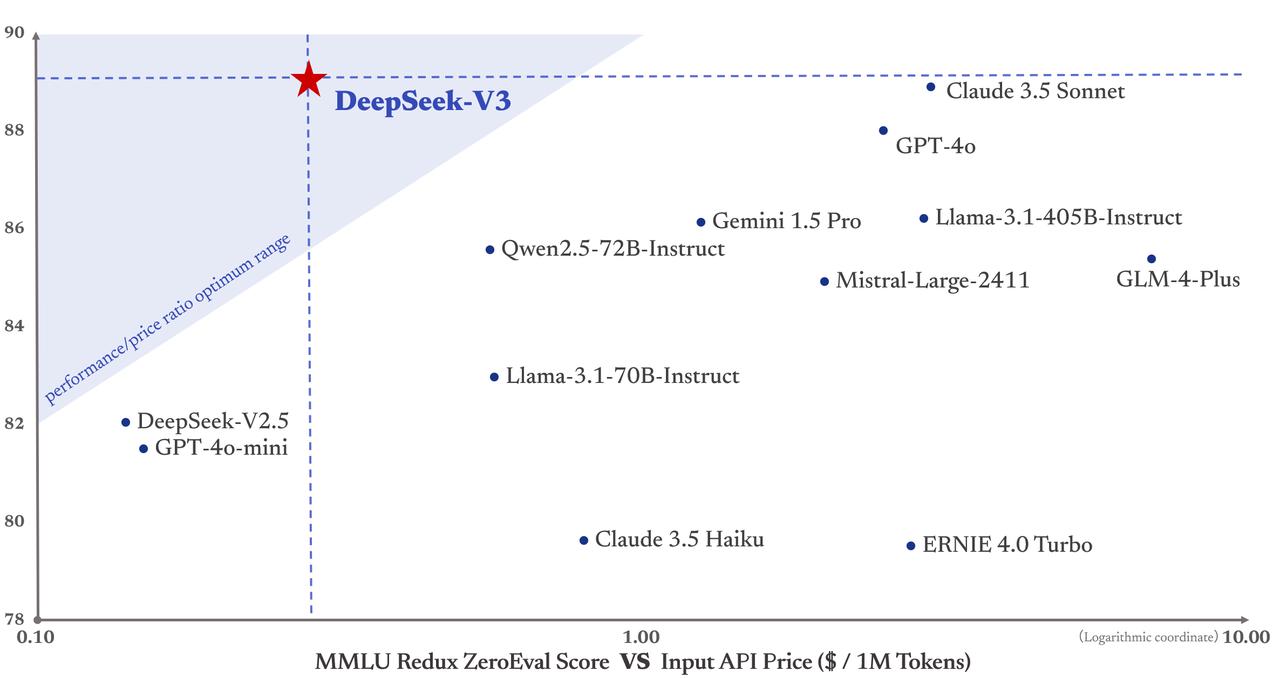
 But the essential point right here is that Liang has found a way to construct competent models with few sources. The corporate's newest models DeepSeek-V3 and DeepSeek-R1 have further consolidated its position. Table 6 presents the evaluation outcomes, showcasing that DeepSeek-V3 stands as the very best-performing open-source model. A 671,000-parameter mannequin, DeepSeek-V3 requires significantly fewer assets than its friends, whereas performing impressively in various benchmark assessments with other brands. In contrast, 10 tests that cover precisely the identical code ought to score worse than the one take a look at because they are not including worth. This means that anybody can access the instrument's code and use it to customise the LLM. Users can entry the DeepSeek chat interface developed for the end person at "chat.deepseek". OpenAI, then again, had released the o1 mannequin closed and is already selling it to users solely, even to users, with packages of $20 (€19) to $200 (€192) per 30 days. Alexandr Wang, CEO of ScaleAI, which supplies coaching data to AI models of main players resembling OpenAI and Google, described DeepSeek's product as "an earth-shattering mannequin" in a speech on the World Economic Forum (WEF) in Davos last week.
But the essential point right here is that Liang has found a way to construct competent models with few sources. The corporate's newest models DeepSeek-V3 and DeepSeek-R1 have further consolidated its position. Table 6 presents the evaluation outcomes, showcasing that DeepSeek-V3 stands as the very best-performing open-source model. A 671,000-parameter mannequin, DeepSeek-V3 requires significantly fewer assets than its friends, whereas performing impressively in various benchmark assessments with other brands. In contrast, 10 tests that cover precisely the identical code ought to score worse than the one take a look at because they are not including worth. This means that anybody can access the instrument's code and use it to customise the LLM. Users can entry the DeepSeek chat interface developed for the end person at "chat.deepseek". OpenAI, then again, had released the o1 mannequin closed and is already selling it to users solely, even to users, with packages of $20 (€19) to $200 (€192) per 30 days. Alexandr Wang, CEO of ScaleAI, which supplies coaching data to AI models of main players resembling OpenAI and Google, described DeepSeek's product as "an earth-shattering mannequin" in a speech on the World Economic Forum (WEF) in Davos last week.
It excels in producing machine studying models, writing data pipelines, and crafting complicated AI algorithms with minimal human intervention. After generating an overview, comply with these steps to create your thoughts map. Generating synthetic data is extra useful resource-environment friendly compared to traditional training methods. However, User 2 is working on the latest iPad, leveraging a cellular information connection that's registered to FirstNet (American public safety broadband community operator) and ostensibly the user would be considered a high value target for espionage. As DeepSeek’s stock value elevated, opponents like Nvidia and Oracle suffered important losses, all inside a single day after its launch. While DeepSeek has stunned American rivals, analysts are already warning about what its launch will imply within the West. Who knows if any of that is basically true or if they're merely some form of entrance for the CCP or the Chinese navy. This new Chinese AI model was released on January 10, 2025, and has taken the world by storm. Since DeepSeek is also open-source, impartial researchers can look on the code of the model and take a look at to find out whether or not it is safe.
Simply drag your cursor on the textual content and scan the QR code on your cell to get the app. It is usually pre-trained on challenge-degree code corpus by using a window measurement of 16,000 and an extra fill-in-the-clean job to support project-degree code completion and infilling. A bigger context window allows a mannequin to understand, summarise or analyse longer texts. How did it produce such a model regardless of US restrictions? US chip export restrictions compelled DeepSeek developers to create smarter, more power-efficient algorithms to compensate for his or her lack of computing power. MIT Technology Review reported that Liang had purchased significant stocks of Nvidia A100 chips, a kind currently banned for export to China, long before the US chip sanctions against China. Realising the importance of this inventory for AI training, Liang founded DeepSeek and began using them in conjunction with low-power chips to enhance his fashions. Based in Hangzhou, Zhejiang, DeepSeek is owned and funded by the Chinese hedge fund High-Flyer co-founder Liang Wenfeng, who additionally serves as its CEO.
- 이전글How Ramblers Benefit By Joining A Rambling Club 25.03.21
- 다음글레비트라 파는곳 비아그라 추천 25.03.21
댓글목록
등록된 댓글이 없습니다.