9 Practical Tactics to Show Deepseek Ai Into a Sales Machine
페이지 정보

본문
 Because of this, after cautious investigations, we maintain the original precision (e.g., BF16 or FP32) for the following components: the embedding module, the output head, MoE gating modules, normalization operators, and a spotlight operators. Specially, for a backward chunk, both attention and MLP are further cut up into two components, backward for input and backward for weights, like in ZeroBubble (Qi et al., 2023b). In addition, now we have a PP communication element. A Microsoft spokesperson, as reported by The Register, defined that these worth changes replicate the expanded benefits added over the past 12 years, including enhanced safety with Microsoft Defender, creative tools like Clipchamp, and improvements to core applications akin to Word, Excel, PowerPoint, OneNote, and Outlook. Had DeepSeek been created by geeks at a US university, it would almost certainly have been feted but with out the global tumult of the past two weeks. Model Updates: DeepSeek models are usually updated with new knowledge to enhance accuracy and relevance. Taiwan restricts government use of Chinese AI model Deepseek free over security, privateness, and copyright issues. During training, we preserve the Exponential Moving Average (EMA) of the model parameters for early estimation of the mannequin efficiency after studying charge decay. Moreover, to additional reduce reminiscence and communication overhead in MoE training, we cache and dispatch activations in FP8, whereas storing low-precision optimizer states in BF16.
Because of this, after cautious investigations, we maintain the original precision (e.g., BF16 or FP32) for the following components: the embedding module, the output head, MoE gating modules, normalization operators, and a spotlight operators. Specially, for a backward chunk, both attention and MLP are further cut up into two components, backward for input and backward for weights, like in ZeroBubble (Qi et al., 2023b). In addition, now we have a PP communication element. A Microsoft spokesperson, as reported by The Register, defined that these worth changes replicate the expanded benefits added over the past 12 years, including enhanced safety with Microsoft Defender, creative tools like Clipchamp, and improvements to core applications akin to Word, Excel, PowerPoint, OneNote, and Outlook. Had DeepSeek been created by geeks at a US university, it would almost certainly have been feted but with out the global tumult of the past two weeks. Model Updates: DeepSeek models are usually updated with new knowledge to enhance accuracy and relevance. Taiwan restricts government use of Chinese AI model Deepseek free over security, privateness, and copyright issues. During training, we preserve the Exponential Moving Average (EMA) of the model parameters for early estimation of the mannequin efficiency after studying charge decay. Moreover, to additional reduce reminiscence and communication overhead in MoE training, we cache and dispatch activations in FP8, whereas storing low-precision optimizer states in BF16.
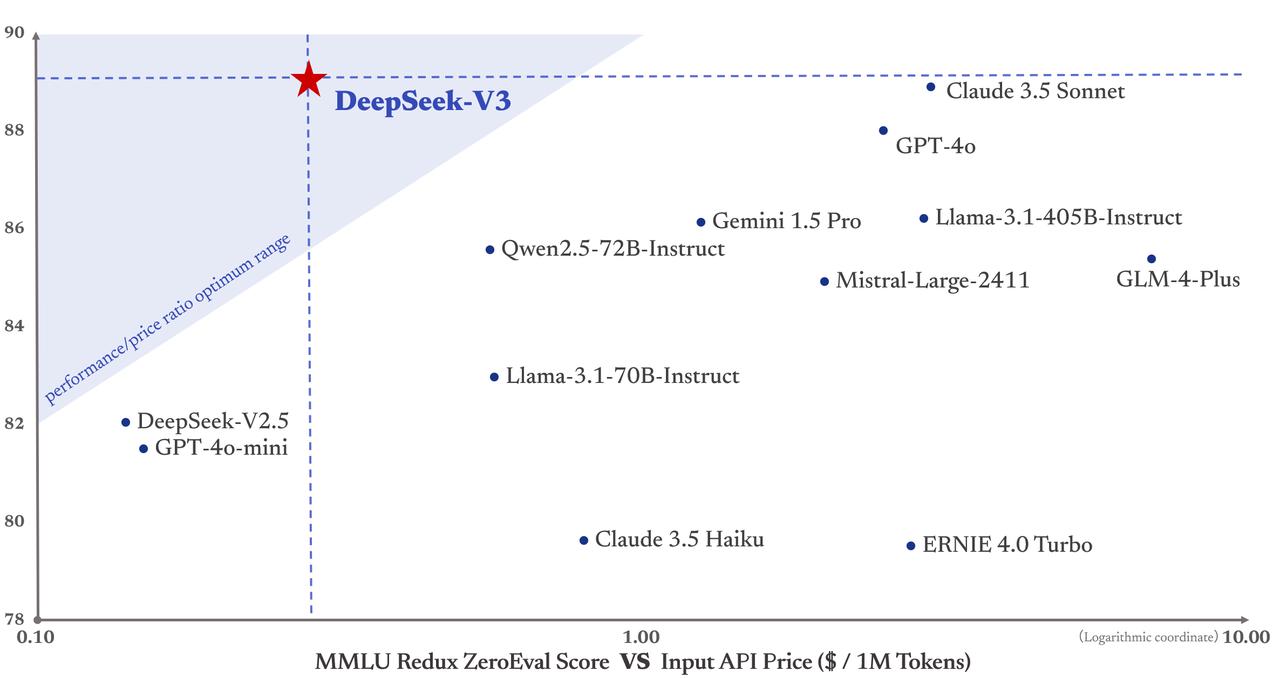 Specifically, we make use of customized PTX (Parallel Thread Execution) directions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs. With a minor overhead, this strategy significantly reduces memory necessities for storing activations. This considerably reduces reminiscence consumption. The opposite trick has to do with how V3 shops data in computer reminiscence. DeepSeek’s domain focus makes it more dependable in delivering accurate, specialised info. The SME FDPR is primarily targeted on ensuring that the superior-node instruments are captured and restricted from the whole of China, whereas the Footnote 5 FDPR applies to a far more expansive record of gear that is restricted to sure Chinese fabs and firms. This is particularly clear in laptops - there are far too many laptops with too little to differentiate them and too many nonsense minor issues. In spite of everything, the quantity of computing energy it takes to construct one impressive model and the amount of computing energy it takes to be the dominant AI mannequin provider to billions of individuals worldwide are very completely different quantities. One can cite a few nits: In the trisection proof, one may favor that the proof embrace a proof why the degrees of subject extensions are multiplicative, however an inexpensive proof of this may be obtained by additional queries.
Specifically, we make use of customized PTX (Parallel Thread Execution) directions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs. With a minor overhead, this strategy significantly reduces memory necessities for storing activations. This considerably reduces reminiscence consumption. The opposite trick has to do with how V3 shops data in computer reminiscence. DeepSeek’s domain focus makes it more dependable in delivering accurate, specialised info. The SME FDPR is primarily targeted on ensuring that the superior-node instruments are captured and restricted from the whole of China, whereas the Footnote 5 FDPR applies to a far more expansive record of gear that is restricted to sure Chinese fabs and firms. This is particularly clear in laptops - there are far too many laptops with too little to differentiate them and too many nonsense minor issues. In spite of everything, the quantity of computing energy it takes to construct one impressive model and the amount of computing energy it takes to be the dominant AI mannequin provider to billions of individuals worldwide are very completely different quantities. One can cite a few nits: In the trisection proof, one may favor that the proof embrace a proof why the degrees of subject extensions are multiplicative, however an inexpensive proof of this may be obtained by additional queries.
It started as Fire-Flyer, a free Deep seek-learning research branch of High-Flyer, one of China’s greatest-performing quantitative hedge funds. China’s National Intelligence Law requires all non-public sector organisations and residents to "support, assist and cooperate" with intelligence agencies. • Harith Iskander’s ‘ham’ joke controversy: A Facebook joke about "ham sup kopi" by comedian Harith Iskander, referencing the KK Mart halal controversy, has snowballed into a full-blown national debate on satire and religious sensitivities. Gemini Advanced is Google's $20 pro version of its Gemini (formerly Bard) chatbot. Winner: Gemini Advanced for its detailed insights. As depicted in Figure 6, all three GEMMs associated with the Linear operator, particularly Fprop (forward pass), Dgrad (activation backward pass), and Wgrad (weight backward pass), are executed in FP8. Additionally, the FP8 Wgrad GEMM permits activations to be saved in FP8 to be used in the backward go. Firstly, with the intention to speed up mannequin training, nearly all of core computation kernels, i.e., GEMM operations, are implemented in FP8 precision. We validate the proposed FP8 blended precision framework on two model scales similar to DeepSeek-V2-Lite and Free Deepseek Online chat-V2, training for roughly 1 trillion tokens (see more particulars in Appendix B.1). This overlap additionally ensures that, because the mannequin additional scales up, so long as we maintain a continuing computation-to-communication ratio, we can nonetheless employ tremendous-grained specialists throughout nodes while attaining a near-zero all-to-all communication overhead.
In this fashion, communications by way of IB and NVLink are absolutely overlapped, and every token can effectively choose a mean of 3.2 consultants per node without incurring further overhead from NVLink. NVLink affords a bandwidth of 160 GB/s, roughly 3.2 times that of IB (50 GB/s). × 3.2 consultants/node) while preserving the identical communication value. Astronomical Costs: Training giant language fashions like GPT-three can value thousands and thousands in compute alone, creating a high barrier to entry. Besides, some low-cost operators may utilize a better precision with a negligible overhead to the general coaching price. Building upon widely adopted methods in low-precision training (Kalamkar et al., 2019; Narang et al., 2017), we propose a blended precision framework for FP8 coaching. As an ordinary apply, the enter distribution is aligned to the representable vary of the FP8 format by scaling the maximum absolute value of the enter tensor to the utmost representable value of FP8 (Narang et al., 2017). This methodology makes low-precision training highly delicate to activation outliers, which may closely degrade quantization accuracy. Despite the effectivity benefit of the FP8 format, certain operators nonetheless require the next precision as a result of their sensitivity to low-precision computations. To additional guarantee numerical stability, we store the grasp weights, weight gradients, and optimizer states in greater precision.
If you beloved this posting and you would like to receive more details pertaining to DeepSeek V3 kindly take a look at the site.
- 이전글The Truth About Your Kitchen Blender 25.03.20
- 다음글Your Key To Success: Ads Network Solutions 25.03.20
댓글목록
등록된 댓글이 없습니다.