Seven Recommendations on Deepseek Ai You Can't Afford To overlook
페이지 정보

본문
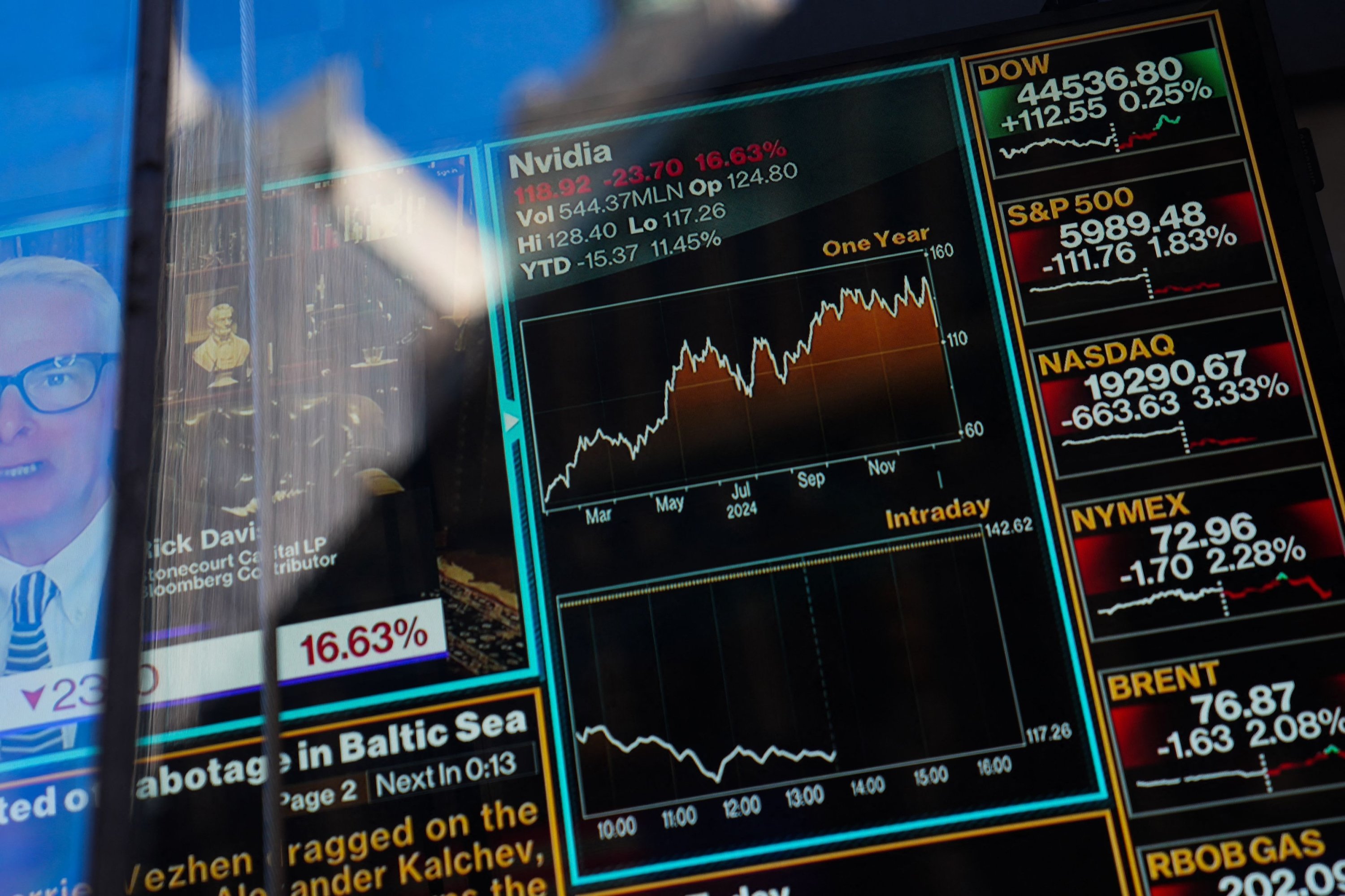 The networking degree optimization might be my favorite half to learn and nerd out about. Meanwhile, when you find yourself resource constrained, or "GPU poor", thus have to squeeze every drop of performance out of what you have, understanding exactly how your infra is constructed and operated can provide you with a leg up in realizing where and how you can optimize. It experienced the biggest drop ever recorded for a U.S. He also prohibited entities on the Entity List, which support China’s army development, Deepseek AI Online chat from updating or utilizing U.S. How much did DeepSeek stockpile, smuggle, or innovate its manner round U.S. Large enterprise clients would possibly proceed paying for top-tier GPT-like reliability, while smaller players lean on open solutions like DeepSeek. So that’s the one piece that is totally different is that this model, although it’s large, it’s open supply. The NVIDIA H800 is permitted for export - it’s primarily a nerfed model of the powerful NVIDIA H100 GPU. Trained on simply 2,048 NVIDIA H800 GPUs over two months, DeepSeek-V3 utilized 2.6 million GPU hours, per the DeepSeek-V3 technical report, at a value of roughly $5.6 million - a stark contrast to the lots of of tens of millions sometimes spent by main American tech firms.
The networking degree optimization might be my favorite half to learn and nerd out about. Meanwhile, when you find yourself resource constrained, or "GPU poor", thus have to squeeze every drop of performance out of what you have, understanding exactly how your infra is constructed and operated can provide you with a leg up in realizing where and how you can optimize. It experienced the biggest drop ever recorded for a U.S. He also prohibited entities on the Entity List, which support China’s army development, Deepseek AI Online chat from updating or utilizing U.S. How much did DeepSeek stockpile, smuggle, or innovate its manner round U.S. Large enterprise clients would possibly proceed paying for top-tier GPT-like reliability, while smaller players lean on open solutions like DeepSeek. So that’s the one piece that is totally different is that this model, although it’s large, it’s open supply. The NVIDIA H800 is permitted for export - it’s primarily a nerfed model of the powerful NVIDIA H100 GPU. Trained on simply 2,048 NVIDIA H800 GPUs over two months, DeepSeek-V3 utilized 2.6 million GPU hours, per the DeepSeek-V3 technical report, at a value of roughly $5.6 million - a stark contrast to the lots of of tens of millions sometimes spent by main American tech firms.
Following the announcement, main players like ByteDance, Tencent, Baidu, and Alibaba swiftly adopted with price reductions, even chopping costs to below price margins. "Clearly tech stocks are beneath huge strain led by Nvidia as the street will view DeepSeek as a significant perceived menace to US tech dominance and owning this AI Revolution," Wedbush Securities analyst Daniel Ives said in a word. Unlike generic responses, Deepseek AI-powered chatbots analyze past interactions and consumer behavior to provide personalized suggestions and tailor-made assist. Innovative competition additionally requires assist for the innovators. By far the most attention-grabbing part (no less than to a cloud infra nerd like me) is the "Infractructures" part, where the DeepSeek team explained intimately how it managed to reduce the fee of training at the framework, knowledge format, and DeepSeek Chat networking stage. I don’t pretend to understand every technical detail within the paper. However, having to work with another team or company to acquire your compute resources also provides each technical and coordination prices, as a result of every cloud works just a little otherwise. If you combine the first two idiosyncratic advantages - no enterprise mannequin plus operating your own datacenter - you get the third: a high degree of software optimization expertise on restricted hardware resources.
Mixture-of consultants (MoE) combine a number of small fashions to make better predictions-this system is utilized by ChatGPT, Mistral, and Qwen. To hedge towards the worst, the United States wants to better perceive the technical risks, how China views those dangers, and what interventions can meaningfully scale back the danger in each countries. Can India Create The subsequent DeepSeek? To reduce networking congestion and get probably the most out of the valuable few H800s it possesses, DeepSeek designed its personal load-balancing communications kernel to optimize the bandwidth variations between NVLink and Infiniband to maximise cross-node all-to-all communications between the GPUs, so every chip is all the time fixing some kind of partial reply and never have to wait around for something to do. At the heart of coaching any giant AI models is parallel processing, the place every accelerator chip calculates a partial reply to all the complex mathematical equations before aggregating all of the elements into the ultimate reply. Thus, the efficiency of your parallel processing determines how well you can maximize the compute power of your GPU cluster. To extend training effectivity, this framework included a new and improved parallel processing algorithm, DualPipe. This framework also changed most of the input values’ data format to floating level eight or FP8.
 Its training framework is constructed from scratch by DeepSeek engineers, referred to as the HAI-LLM framework. Nathan Lambert just lately published an excellent breakdown of DeepSeek v3 (https://www.dnnsoftware.com)’s technical improvements and probed more deeply into the $6m coaching costs declare. The information associated to DeepSeek has already resulted in some sizable losses to Nvidia's market cap, however may this be just the beginning -- is extra of a sell-off coming? However, what DeepSeek has achieved could also be hard to replicate elsewhere. For now, prominent local weather activist Bill McKibben sees the introduction of Deepseek Online chat as a potential climate win. Since we know that DeepSeek used 2048 H800s, there are likely 256 nodes of 8-GPU servers, connected by Infiniband. There were additionally loads of files with lengthy licence and copyright statements. Not needing to manage your individual infrastructure and simply assuming that the GPUs might be there frees up the R&D workforce to do what they're good at, which is not managing infrastructure. Science Minister Ed Husic was among the primary Western leaders to warn that there were "unanswered questions" about the platform's knowledge and privateness administration late last month.
Its training framework is constructed from scratch by DeepSeek engineers, referred to as the HAI-LLM framework. Nathan Lambert just lately published an excellent breakdown of DeepSeek v3 (https://www.dnnsoftware.com)’s technical improvements and probed more deeply into the $6m coaching costs declare. The information associated to DeepSeek has already resulted in some sizable losses to Nvidia's market cap, however may this be just the beginning -- is extra of a sell-off coming? However, what DeepSeek has achieved could also be hard to replicate elsewhere. For now, prominent local weather activist Bill McKibben sees the introduction of Deepseek Online chat as a potential climate win. Since we know that DeepSeek used 2048 H800s, there are likely 256 nodes of 8-GPU servers, connected by Infiniband. There were additionally loads of files with lengthy licence and copyright statements. Not needing to manage your individual infrastructure and simply assuming that the GPUs might be there frees up the R&D workforce to do what they're good at, which is not managing infrastructure. Science Minister Ed Husic was among the primary Western leaders to warn that there were "unanswered questions" about the platform's knowledge and privateness administration late last month.
- 이전글카마그라젤효능, 비아그라정품판매처 25.03.07
- 다음글Deepseek Ai - Are You Ready For A superb Factor? 25.03.07
댓글목록
등록된 댓글이 없습니다.