Will Deepseek Ai News Ever Die?
페이지 정보

본문
We famous that LLMs can perform mathematical reasoning using both text and programs. All of the models are very superior and might simply generate good textual content templates like emails or fetch data from the web and display nonetheless you need, for instance. It’s non-trivial to master all these required capabilities even for humans, not to mention language fashions. It’s easy to see the mixture of methods that lead to giant efficiency gains in contrast with naive baselines. We see the progress in effectivity - quicker generation velocity at lower price. Generation is best than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection. The second downside falls underneath extremal combinatorics, a subject beyond the scope of high school math. In general, the issues in AIMO have been significantly extra challenging than these in GSM8K, a normal mathematical reasoning benchmark for LLMs, and about as difficult as the hardest issues in the challenging MATH dataset.
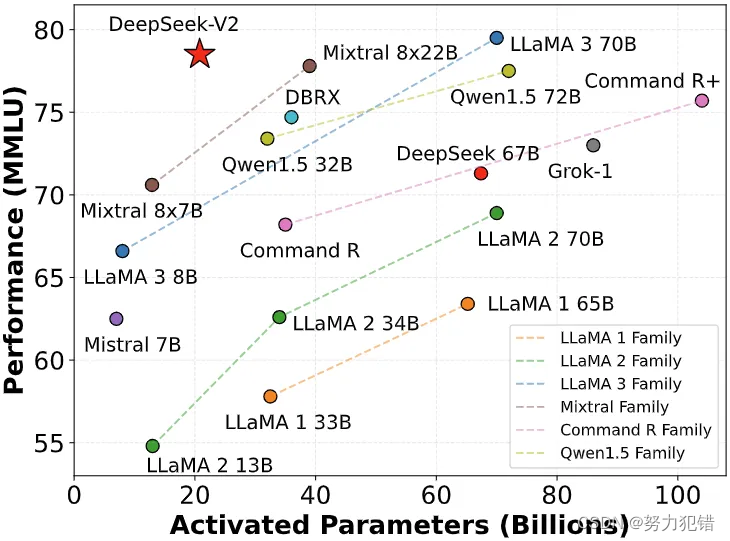 This resulted in a dataset of 2,600 problems. This resulted in DeepSeek-V2. Then it proceeded to provide me written steps instead of a circulation chart. Gemini simply pulled a move chart image from the web that reveals how to create circulate charts as an alternative of Wi-Fi troubleshooting points. Only Gemini was capable of reply this though we are using an outdated Gemini 1.5 model. Similarly, within the HumanEval Python take a look at, the mannequin improved its rating from 84.5 to 89. These metrics are a testament to the significant developments normally-purpose reasoning, coding skills, and human-aligned responses. DeepSeek R1 demonstrates distinctive accuracy in structured reasoning duties, particularly in mathematics and coding. Additionally, DeepSeek Coder and DeepSeek Coderv deal with coding and syntax solutions, typically outperforming ChatGPT in offering nicely-structured programming assist. But once i requested for an explanation, both ChatGPT and Gemini defined it in 10-20 traces at max. Within the Aider LLM Leaderboard, DeepSeek V3 is presently in second place, dethroning GPT-4o, Claude 3.5 Sonnet, and even the newly announced Gemini 2.0. It comes second solely to the o1 reasoning model, which takes minutes to generate a outcome. The most effective part is DeepSeek educated their V3 mannequin with simply $5.5 million in comparison with OpenAI’s $100 Million investment (talked about by Sam Altman).
This resulted in a dataset of 2,600 problems. This resulted in DeepSeek-V2. Then it proceeded to provide me written steps instead of a circulation chart. Gemini simply pulled a move chart image from the web that reveals how to create circulate charts as an alternative of Wi-Fi troubleshooting points. Only Gemini was capable of reply this though we are using an outdated Gemini 1.5 model. Similarly, within the HumanEval Python take a look at, the mannequin improved its rating from 84.5 to 89. These metrics are a testament to the significant developments normally-purpose reasoning, coding skills, and human-aligned responses. DeepSeek R1 demonstrates distinctive accuracy in structured reasoning duties, particularly in mathematics and coding. Additionally, DeepSeek Coder and DeepSeek Coderv deal with coding and syntax solutions, typically outperforming ChatGPT in offering nicely-structured programming assist. But once i requested for an explanation, both ChatGPT and Gemini defined it in 10-20 traces at max. Within the Aider LLM Leaderboard, DeepSeek V3 is presently in second place, dethroning GPT-4o, Claude 3.5 Sonnet, and even the newly announced Gemini 2.0. It comes second solely to the o1 reasoning model, which takes minutes to generate a outcome. The most effective part is DeepSeek educated their V3 mannequin with simply $5.5 million in comparison with OpenAI’s $100 Million investment (talked about by Sam Altman).
DeepSeek-R1 is not only remarkably efficient, however additionally it is way more compact and fewer computationally costly than competing AI software program, such as the latest model ("o1-1217") of OpenAI’s chatbot. When he isn't breaking down the most recent tech, he is typically immersed in a classic movie - a real cinephile at heart. The newest model, DeepSeek-R1, released in January 2025, focuses on logical inference, mathematical reasoning, and actual-time problem-fixing. This strategy stemmed from our examine on compute-optimum inference, demonstrating that weighted majority voting with a reward model constantly outperforms naive majority voting given the same inference budget. Our closing solutions were derived via a weighted majority voting system, which consists of producing multiple options with a coverage mannequin, assigning a weight to every resolution utilizing a reward model, and then selecting the answer with the highest whole weight. Our ultimate solutions were derived by a weighted majority voting system, the place the solutions have been generated by the coverage model and the weights have been determined by the scores from the reward mannequin. In accordance with Sensor Tower, by July 2024, CapCut had generated $125 million in cumulative income from mobile functions.
Second, based on estimates, the mannequin solely value $5.6 million to prepare, a tiny fraction of what it costs to prepare most AI fashions. Thus, it was crucial to make use of acceptable fashions and inference strategies to maximize accuracy inside the constraints of restricted memory and FLOPs. We used the accuracy on a chosen subset of the MATH take a look at set because the analysis metric. With FP8 precision and DualPipe parallelism, DeepSeek-V3 minimizes energy consumption whereas sustaining accuracy. However, researchers at DeepSeek said in a recent paper that the DeepSeek-V3 mannequin was trained using Nvidia's H800 chips, a less superior alternative not coated by the restrictions. Is DeepSeek a win for Apple? But WIRED reviews, external that for years, Free Deepseek Online chat founder Liang Wenfung's hedge fund High-Flyer has been stockpiling the chips that form the backbone of AI - generally known as GPUs, or graphics processing items. Liang already attended an essential assembly with Chinese Premier Li Qiang last week.
- 이전글Bophut Hotels Offer Variety And Luxury 25.02.28
- 다음글Links 25/5/2025: Nginx 1.11, F1 2025 Coming To GNU/Linux Tomorrow 25.02.28
댓글목록
등록된 댓글이 없습니다.