Taking Stock of The DeepSeek Shock
페이지 정보

본문
 ? Unparalleled effectivity Leverage DeepSeek chat for actual-time conversations, pulling relevant data from scattered recordsdata within seconds. Now with these open ‘reasoning’ fashions, build agent programs that can much more intelligently motive in your knowledge. DeepSeek’s use of synthetic data isn’t revolutionary, both, although it does present that it’s possible for AI labs to create one thing helpful without robbing your entire internet. In 2025 frontier labs use MMLU Pro, GPQA Diamond, and Big-Bench Hard. With Gemini 2.Zero also being natively voice and vision multimodal, the Voice and Vision modalities are on a clear path to merging in 2025 and beyond. AudioPaLM paper - our last look at Google’s voice ideas before PaLM became Gemini. We suggest having working expertise with vision capabilities of 4o (together with finetuning 4o imaginative and prescient), Claude 3.5 Sonnet/Haiku, Gemini 2.Zero Flash, and o1. Many regard 3.5 Sonnet as the most effective code mannequin nevertheless it has no paper. DPO paper - the favored, if slightly inferior, various to PPO, now supported by OpenAI as Preference Finetuning.
? Unparalleled effectivity Leverage DeepSeek chat for actual-time conversations, pulling relevant data from scattered recordsdata within seconds. Now with these open ‘reasoning’ fashions, build agent programs that can much more intelligently motive in your knowledge. DeepSeek’s use of synthetic data isn’t revolutionary, both, although it does present that it’s possible for AI labs to create one thing helpful without robbing your entire internet. In 2025 frontier labs use MMLU Pro, GPQA Diamond, and Big-Bench Hard. With Gemini 2.Zero also being natively voice and vision multimodal, the Voice and Vision modalities are on a clear path to merging in 2025 and beyond. AudioPaLM paper - our last look at Google’s voice ideas before PaLM became Gemini. We suggest having working expertise with vision capabilities of 4o (together with finetuning 4o imaginative and prescient), Claude 3.5 Sonnet/Haiku, Gemini 2.Zero Flash, and o1. Many regard 3.5 Sonnet as the most effective code mannequin nevertheless it has no paper. DPO paper - the favored, if slightly inferior, various to PPO, now supported by OpenAI as Preference Finetuning.
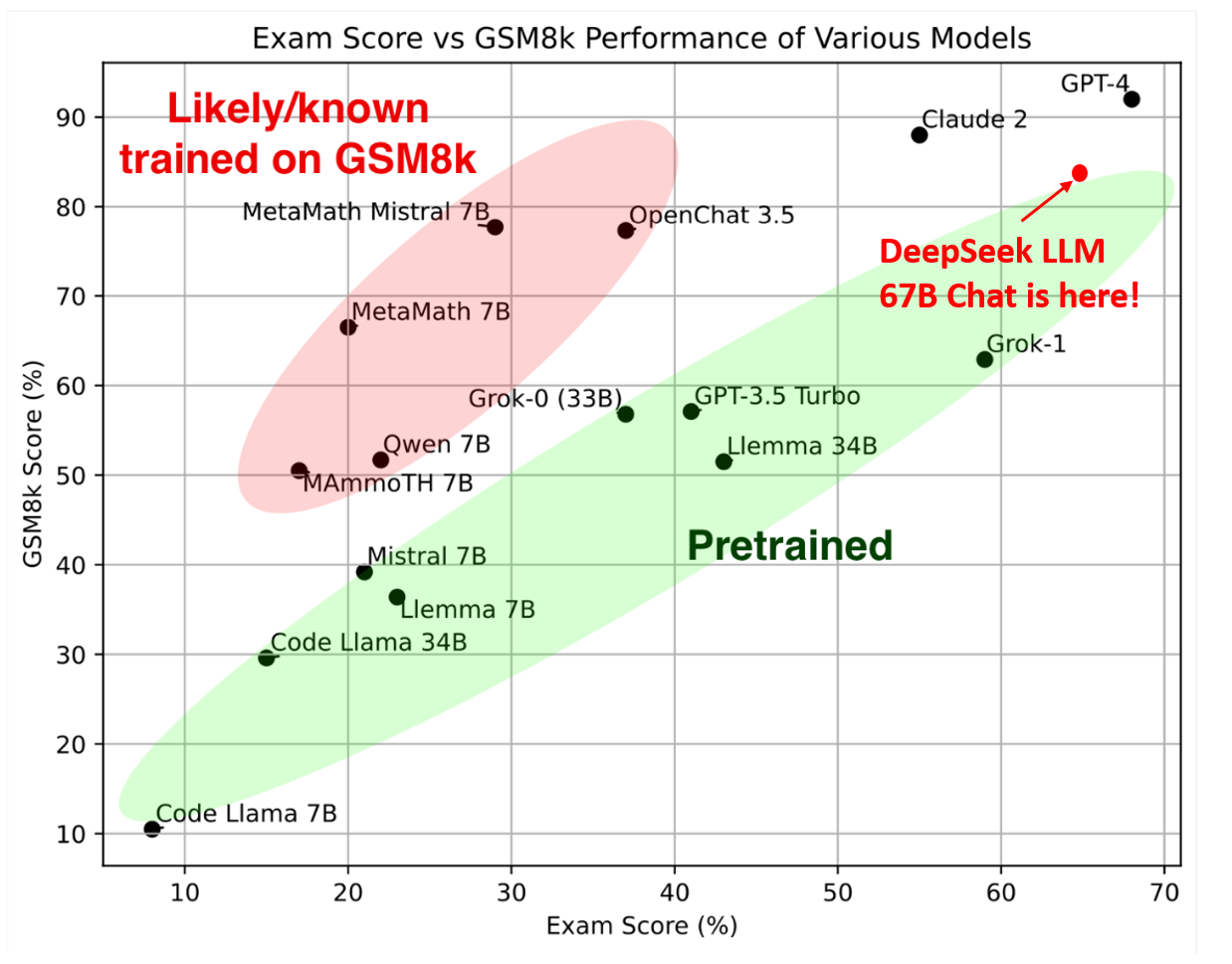 RAGAS paper - the simple RAG eval recommended by OpenAI. Imagen / Imagen 2 / Imagen 3 paper - Google’s image gen. See additionally Ideogram. DALL-E / DALL-E-2 / DALL-E-3 paper - OpenAI’s picture generation. Text Diffusion, Music Diffusion, and autoregressive picture technology are area of interest but rising. "Free DeepSeek online represents a new technology of Chinese tech corporations that prioritize lengthy-time period technological development over quick commercialization," says Zhang. "Nvidia’s growth expectations were definitely a little bit ‘optimistic’ so I see this as a necessary response," says Naveen Rao, Databricks VP of AI. To see why, consider that any massive language mannequin probably has a small quantity of data that it uses rather a lot, whereas it has rather a lot of knowledge that it makes use of reasonably infrequently. Introduction to Information Retrieval - a bit unfair to advocate a book, but we are attempting to make the point that RAG is an IR downside and IR has a 60 yr historical past that features TF-IDF, BM25, FAISS, HNSW and other "boring" methods. One among the most popular traits in RAG in 2024, alongside of ColBERT/ColPali/ColQwen (more in the Vision section).
RAGAS paper - the simple RAG eval recommended by OpenAI. Imagen / Imagen 2 / Imagen 3 paper - Google’s image gen. See additionally Ideogram. DALL-E / DALL-E-2 / DALL-E-3 paper - OpenAI’s picture generation. Text Diffusion, Music Diffusion, and autoregressive picture technology are area of interest but rising. "Free DeepSeek online represents a new technology of Chinese tech corporations that prioritize lengthy-time period technological development over quick commercialization," says Zhang. "Nvidia’s growth expectations were definitely a little bit ‘optimistic’ so I see this as a necessary response," says Naveen Rao, Databricks VP of AI. To see why, consider that any massive language mannequin probably has a small quantity of data that it uses rather a lot, whereas it has rather a lot of knowledge that it makes use of reasonably infrequently. Introduction to Information Retrieval - a bit unfair to advocate a book, but we are attempting to make the point that RAG is an IR downside and IR has a 60 yr historical past that features TF-IDF, BM25, FAISS, HNSW and other "boring" methods. One among the most popular traits in RAG in 2024, alongside of ColBERT/ColPali/ColQwen (more in the Vision section).
RAG is the bread and butter of AI Engineering at work in 2024, so there are numerous trade assets and sensible experience you'll be anticipated to have. In 2025, the frontier (o1, o3, R1, QwQ/QVQ, f1) can be very a lot dominated by reasoning models, which have no direct papers, but the essential information is Let’s Verify Step By Step4, STaR, and Noam Brown’s talks/podcasts. Frontier labs focus on FrontierMath and onerous subsets of MATH: MATH level 5, AIME, AMC10/AMC12. Within the high-stakes domain of frontier AI, Trump’s transactional strategy to international policy might show conducive to breakthrough agreements - even, or especially, with China. On Monday, Nvidia, which holds a near-monopoly on producing the semiconductors that energy generative AI, misplaced almost $600bn in market capitalisation after its shares plummeted 17 %. Solving Lost in the Middle and other issues with Needle in a Haystack. CriticGPT paper - LLMs are known to generate code that can have safety issues. MMVP benchmark (LS Live)- quantifies vital points with CLIP. CLIP paper - the primary successful ViT from Alec Radford. This is the minimum bar that I count on very elite programmers ought to be striving for within the age of AI and DeepSeek needs to be studied as an example and that is the only just the primary of many tasks from them.There may be an extremely excessive chance (the truth is a 99.9% probability) that an AI didn't construct this and the ones who're able to build or adapt projects like this that are deep into hardware systems will likely be probably the most type after.Not the horrendous JS or even TS slop throughout GitHub that's extraordinarily easy for an AI to generate correctly.You've acquired till 2030 to determine.
We additionally highly recommend familiarity with ComfyUI (we had been first to interview). ReAct paper (our podcast) - ReAct started a protracted line of research on software utilizing and operate calling LLMs, including Gorilla and the BFCL Leaderboard. Consult with this step-by-step guide on find out how to deploy DeepSeek-R1-Distill fashions utilizing Amazon Bedrock Custom Model Import. Honorable mentions of LLMs to know: AI2 (Olmo, Molmo, OlmOE, Tülu 3, Olmo 2), Grok, Amazon Nova, Yi, Reka, Jamba, Cohere, Nemotron, Microsoft Phi, HuggingFace SmolLM - principally lower in ranking or lack papers. Open Code Model papers - select from DeepSeek-Coder, Qwen2.5-Coder, or CodeLlama. Many embeddings have papers - decide your poison - SentenceTransformers, OpenAI, Nomic Embed, Jina v3, cde-small-v1, ModernBERT Embed - with Matryoshka embeddings more and more standard. Whisper v2, v3 and distil-whisper and v3 Turbo are open weights but don't have any paper. Sora blogpost - textual content to video - no paper after all beyond the DiT paper (same authors), but nonetheless the most important launch of the yr, with many open weights competitors like OpenSora. Early fusion analysis: Contra the cheap "late fusion" work like LLaVA (our pod), early fusion covers Meta’s Flamingo, Chameleon, Apple’s AIMv2, Reka Core, et al.
- 이전글5 Mistakes In Deepseek Chatgpt That Make You Look Dumb 25.02.28
- 다음글Three Greatest Moments In Buy Category B Driving License History 25.02.28
댓글목록
등록된 댓글이 없습니다.