Ten DIY Deepseek Chatgpt Ideas You'll have Missed
페이지 정보

본문
 The React workforce would need to list some instruments, but at the identical time, most likely that's a list that would ultimately need to be upgraded so there's undoubtedly quite a lot of planning required right here, too. I might say that’s a variety of it. BLOOM (BigScience Large Open-science Open-entry Multilingual Language Model) BLOOM is a household of fashions released by BigScience, a collaborative effort including a thousand researchers throughout 60 nations and 250 establishments, coordinated by Hugging Face, in collaboration with the French organizations GENCI and IDRIS. When comparing AI fashions like DeepSeek, ChatGPT, and Gemini, one among the primary elements to think about is velocity and accuracy. This is partly because of the perceived benefit of being the first to develop superior AI know-how. The platform is actively maintained and recurrently updated with new features and enhancements, guaranteeing a seamless person experience and conserving pace with developments in AI know-how. Enjoy quicker speeds and complete options designed to answer your questions and enhance your life effectively. DeepSeek also lately debuted DeepSeek-R1-Lite-Preview, a language model that wraps in reinforcement studying to get better efficiency. There was a type of ineffable spark creeping into it - for lack of a better word, personality.
The React workforce would need to list some instruments, but at the identical time, most likely that's a list that would ultimately need to be upgraded so there's undoubtedly quite a lot of planning required right here, too. I might say that’s a variety of it. BLOOM (BigScience Large Open-science Open-entry Multilingual Language Model) BLOOM is a household of fashions released by BigScience, a collaborative effort including a thousand researchers throughout 60 nations and 250 establishments, coordinated by Hugging Face, in collaboration with the French organizations GENCI and IDRIS. When comparing AI fashions like DeepSeek, ChatGPT, and Gemini, one among the primary elements to think about is velocity and accuracy. This is partly because of the perceived benefit of being the first to develop superior AI know-how. The platform is actively maintained and recurrently updated with new features and enhancements, guaranteeing a seamless person experience and conserving pace with developments in AI know-how. Enjoy quicker speeds and complete options designed to answer your questions and enhance your life effectively. DeepSeek also lately debuted DeepSeek-R1-Lite-Preview, a language model that wraps in reinforcement studying to get better efficiency. There was a type of ineffable spark creeping into it - for lack of a better word, personality.
The authors additionally made an instruction-tuned one which does somewhat better on a number of evals. About DeepSeek: DeepSeek makes some extraordinarily good massive language fashions and has also revealed a number of intelligent ideas for further enhancing how it approaches AI coaching. My private laptop is a 64GB M2 MackBook Pro from 2023. It's a powerful machine, but it is also almost two years outdated now - and crucially it is the same laptop I've been utilizing ever since I first ran an LLM on my laptop again in March 2023 (see Large language fashions are having their Stable Diffusion second). The best is but to come: "While INTELLECT-1 demonstrates encouraging benchmark results and represents the primary model of its size efficiently educated on a decentralized network of GPUs, it still lags behind current state-of-the-art fashions educated on an order of magnitude more tokens," they write. Moreover, the upper storage necessities for on-machine processing and personalised models may also open up new avenues for monetization for DeepSeek site Apple. Alibaba’s Qwen mannequin is the world’s finest open weight code mannequin (Import AI 392) - they usually achieved this by way of a combination of algorithmic insights and entry to data (5.5 trillion prime quality code/math ones). That night, he checked on the positive-tuning job and browse samples from the mannequin.
Read more: INTELLECT-1 Release: The primary Globally Trained 10B Parameter Model (Prime Intellect blog). Anyone wish to take bets on when we’ll see the primary 30B parameter distributed training run? Shortly before this subject of Import AI went to press, Nous Research announced that it was in the method of training a 15B parameter LLM over the web using its personal distributed coaching techniques as effectively. "This run presents a loss curve and convergence fee that meets or exceeds centralized training," Nous writes. The training run was based mostly on a Nous approach known as Distributed Training Over-the-Internet (DisTro, Import AI 384) and Nous has now printed additional particulars on this strategy, which I’ll cover shortly. DeepSeek was the primary firm to publicly match OpenAI, which earlier this 12 months launched the o1 class of fashions which use the identical RL method - an extra signal of how subtle DeepSeek is. Before orchestrating agentic workflows with CrewAI powered by an LLM, the first step is to host and question an LLM utilizing SageMaker actual-time inference endpoints.
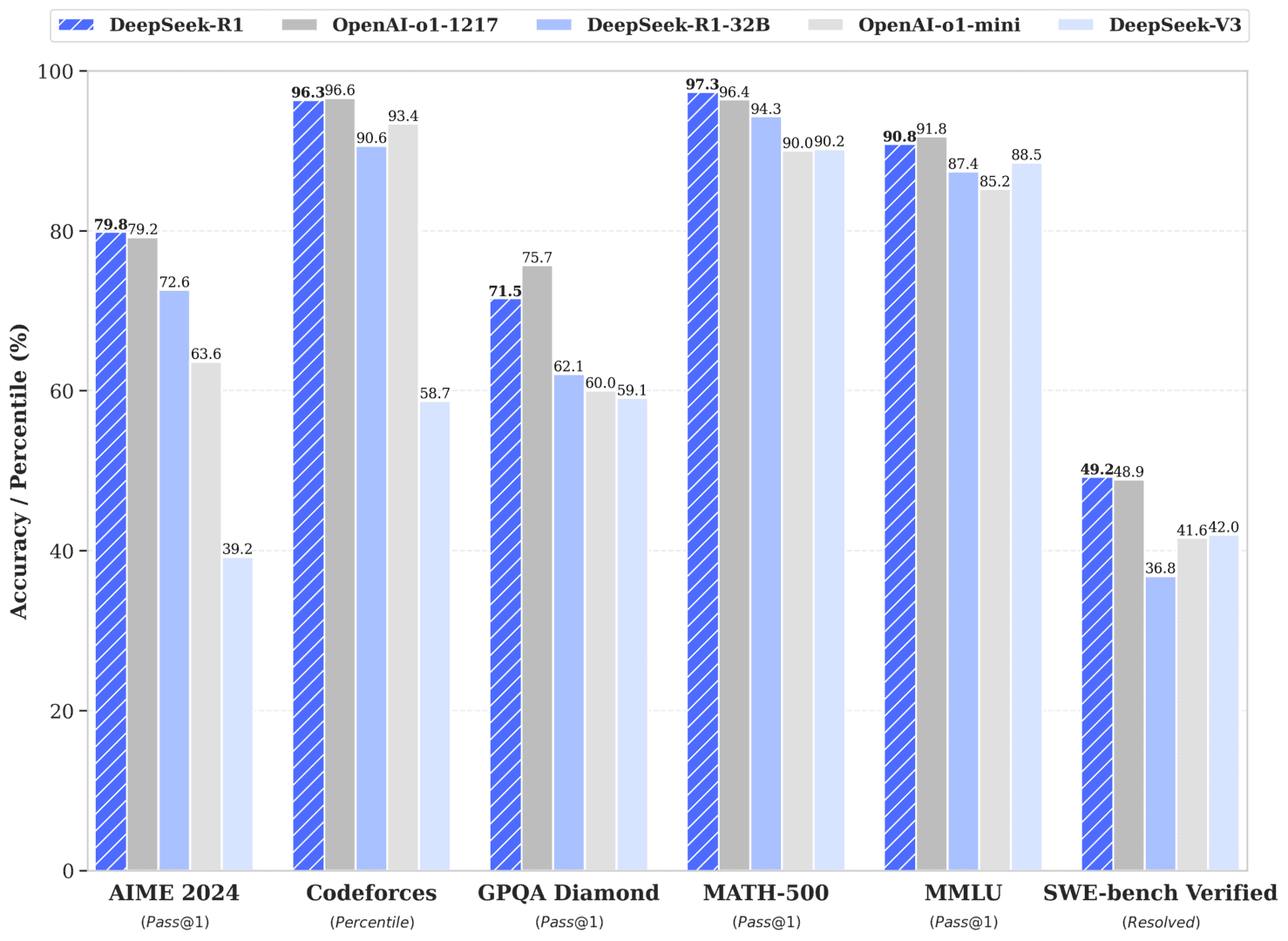 If you are gonna decide to using all this political capital to expend with allies and industry, spend months drafting a rule, you need to be committed to truly implementing it. On the time, the US was considered to have been caught off-guard by their rival's technological achievement. This is why the world’s most highly effective models are both made by massive corporate behemoths like Facebook and Google, or by startups that have raised unusually giant amounts of capital (OpenAI, Anthropic, XAI). The price of decentralization: An essential caveat to all of this is none of this comes without spending a dime - coaching models in a distributed method comes with hits to the efficiency with which you mild up every GPU throughout coaching. 8.64E19 FLOP. Also, solely the most important model's cost is written. The most recent DeepSeek mannequin also stands out as a result of its "weights" - the numerical parameters of the model obtained from the training course of - have been brazenly released, together with a technical paper describing the mannequin's development course of. Why this matters - compute is the only thing standing between Chinese AI firms and the frontier labs in the West: This interview is the most recent instance of how access to compute is the only remaining factor that differentiates Chinese labs from Western labs.
If you are gonna decide to using all this political capital to expend with allies and industry, spend months drafting a rule, you need to be committed to truly implementing it. On the time, the US was considered to have been caught off-guard by their rival's technological achievement. This is why the world’s most highly effective models are both made by massive corporate behemoths like Facebook and Google, or by startups that have raised unusually giant amounts of capital (OpenAI, Anthropic, XAI). The price of decentralization: An essential caveat to all of this is none of this comes without spending a dime - coaching models in a distributed method comes with hits to the efficiency with which you mild up every GPU throughout coaching. 8.64E19 FLOP. Also, solely the most important model's cost is written. The most recent DeepSeek mannequin also stands out as a result of its "weights" - the numerical parameters of the model obtained from the training course of - have been brazenly released, together with a technical paper describing the mannequin's development course of. Why this matters - compute is the only thing standing between Chinese AI firms and the frontier labs in the West: This interview is the most recent instance of how access to compute is the only remaining factor that differentiates Chinese labs from Western labs.
If you enjoyed this post and you would like to receive even more facts regarding شات DeepSeek kindly check out our web site.
- 이전글Apply Any Of those Seven Secret Techniques To enhance Sports Betting Information Website 25.02.14
- 다음글신용카드한도현금화 문제성 및 예방정보 정리 25.02.14
댓글목록
등록된 댓글이 없습니다.