If Deepseek Is So Bad, Why Don't Statistics Show It?
페이지 정보

본문
DeepSeek excels in duties comparable to arithmetic, math, reasoning, and coding, surpassing even some of the most renowned fashions like GPT-4 and LLaMA3-70B. Better & faster massive language fashions through multi-token prediction. In addition to the MLA and DeepSeekMoE architectures, it also pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training goal for stronger performance. Based on our analysis, the acceptance charge of the second token prediction ranges between 85% and 90% throughout varied generation matters, demonstrating consistent reliability. A pure query arises concerning the acceptance fee of the additionally predicted token. PIQA: reasoning about bodily commonsense in pure language. The Pile: An 800GB dataset of various text for language modeling. Measuring mathematical problem fixing with the math dataset. A span-extraction dataset for Chinese machine studying comprehension. Chinese simpleqa: A chinese language factuality analysis for giant language models. C-Eval: A multi-stage multi-discipline chinese language analysis suite for basis models. Deepseekmoe: Towards ultimate professional specialization in mixture-of-experts language models. This research represents a major step ahead in the sector of giant language fashions for mathematical reasoning, and it has the potential to influence various domains that rely on superior mathematical expertise, corresponding to scientific analysis, engineering, and training. This release marks a big step in the direction of closing the gap between open and closed AI fashions.
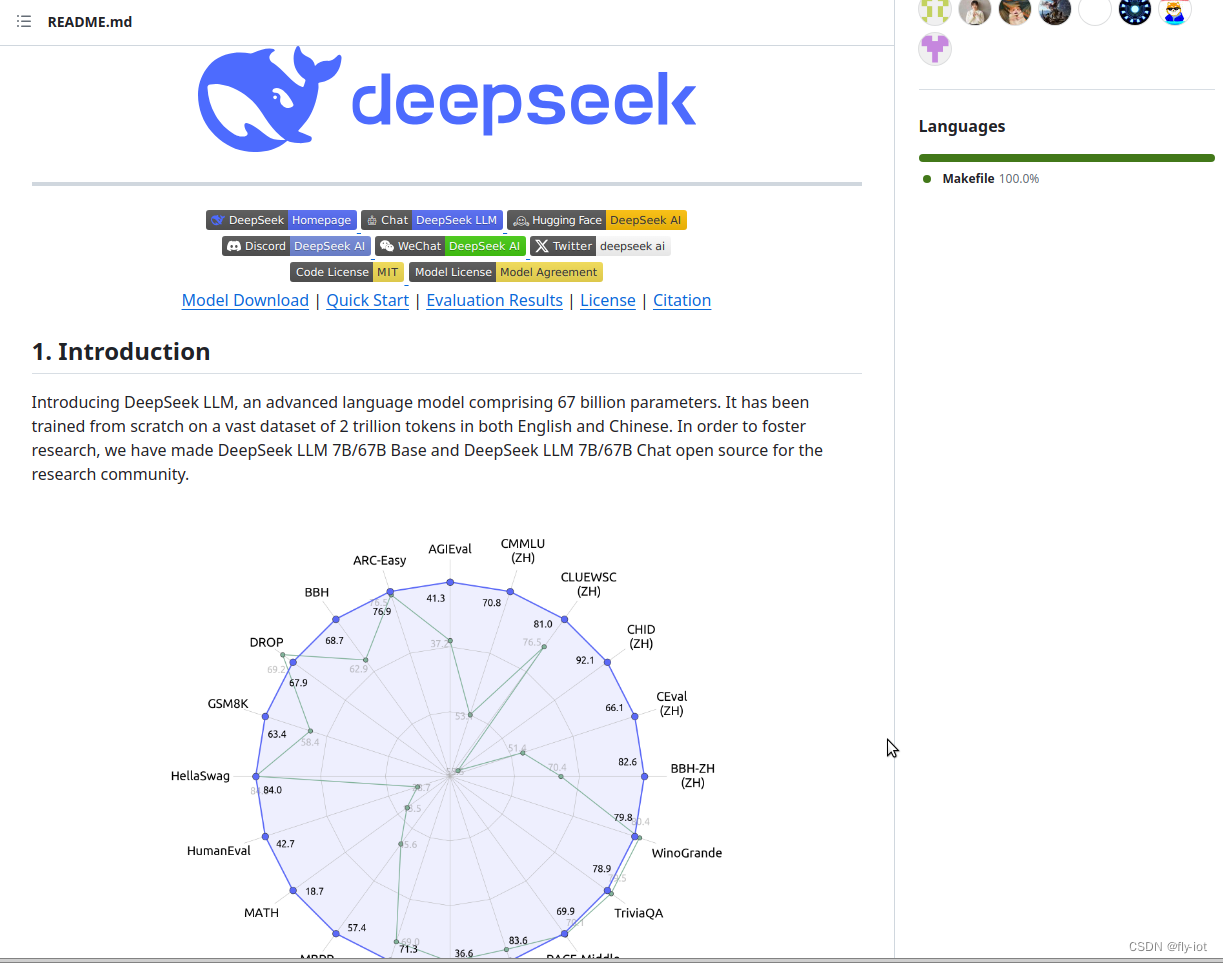 DeepSeek persistently adheres to the route of open-source fashions with longtermism, aiming to steadily approach the last word aim of AGI (Artificial General Intelligence). Step 2: Further Pre-training utilizing an extended 16K window size on an additional 200B tokens, leading to foundational models (DeepSeek-Coder-Base). The next step is in fact "we need to build gods and put them in the whole lot". No need to threaten the mannequin or deliver grandma into the prompt. Deepseek-coder: When the massive language mannequin meets programming - the rise of code intelligence. The out there knowledge sets are additionally typically of poor high quality; we checked out one open-source coaching set, and it included more junk with the extension .sol than bona fide Solidity code. Training verifiers to resolve math phrase problems. It pushes the boundaries of AI by fixing advanced mathematical issues akin to these within the International Mathematical Olympiad (IMO). AlphaGeometry relies on self-play to generate geometry proofs, whereas DeepSeek-Prover uses present mathematical problems and routinely formalizes them into verifiable Lean four proofs.
DeepSeek persistently adheres to the route of open-source fashions with longtermism, aiming to steadily approach the last word aim of AGI (Artificial General Intelligence). Step 2: Further Pre-training utilizing an extended 16K window size on an additional 200B tokens, leading to foundational models (DeepSeek-Coder-Base). The next step is in fact "we need to build gods and put them in the whole lot". No need to threaten the mannequin or deliver grandma into the prompt. Deepseek-coder: When the massive language mannequin meets programming - the rise of code intelligence. The out there knowledge sets are additionally typically of poor high quality; we checked out one open-source coaching set, and it included more junk with the extension .sol than bona fide Solidity code. Training verifiers to resolve math phrase problems. It pushes the boundaries of AI by fixing advanced mathematical issues akin to these within the International Mathematical Olympiad (IMO). AlphaGeometry relies on self-play to generate geometry proofs, whereas DeepSeek-Prover uses present mathematical problems and routinely formalizes them into verifiable Lean four proofs.
I've tried building many brokers, and honestly, whereas it is simple to create them, it is an entirely different ball game to get them proper. Get began with CopilotKit utilizing the following command. It enables you to search the net using the identical type of conversational prompts that you simply normally have interaction a chatbot with. The benchmark includes artificial API function updates paired with programming tasks that require utilizing the updated performance, difficult the mannequin to purpose in regards to the semantic adjustments relatively than just reproducing syntax. The effectiveness demonstrated in these specific areas signifies that lengthy-CoT distillation could be beneficial for enhancing model efficiency in different cognitive tasks requiring advanced reasoning. Model Distillation: Create smaller variations tailor-made to specific use cases. Meta has to use their monetary advantages to shut the hole - it is a risk, however not a given. We may even explore its distinctive features, benefits over opponents, and best practices for implementation. In China, the authorized system is often considered to be "rule by law" somewhat than "rule of law." Which means though China has legal guidelines, their implementation and software could also be affected by political and financial factors, in addition to the private interests of those in power.
• We'll discover extra comprehensive and multi-dimensional mannequin evaluation strategies to prevent the tendency towards optimizing a set set of benchmarks during research, which can create a deceptive impression of the model capabilities and have an effect on our foundational evaluation. Compressor summary: The paper investigates how completely different features of neural networks, akin to MaxPool operation and numerical precision, affect the reliability of automatic differentiation and its affect on performance. The performance of an Deepseek mannequin relies upon closely on the hardware it is working on. The second mannequin receives the generated steps and the schema definition, combining the knowledge for SQL generation. Fact, fetch, and reason: A unified analysis of retrieval-augmented generation. During the event of DeepSeek-V3, for these broader contexts, we make use of the constitutional AI method (Bai et al., 2022), leveraging the voting analysis outcomes of DeepSeek-V3 itself as a suggestions supply. On this paper, we introduce DeepSeek-V3, a big MoE language mannequin with 671B total parameters and 37B activated parameters, trained on 14.8T tokens. DeepSeek AI-R1 accomplishes its computational efficiency by employing a mixture of consultants (MoE) structure built upon the DeepSeek site-V3 base model, which laid the groundwork for R1’s multi-domain language understanding.
If you liked this information and you would certainly like to obtain more facts relating to شات ديب سيك kindly browse through our page.
- 이전글Seven Explanations On Why ADHD Online Test Is So Important 25.02.09
- 다음글The Best Ovens Hobs Tricks To Transform Your Life 25.02.09
댓글목록
등록된 댓글이 없습니다.